
En el post anterior
, vimos cómo el compilador transforma SSA optimizado en bytes de código máquina y los empaqueta en archivos objeto. Cada archivo .o contiene el código compilado de un paquete—con instrucciones de máquina, definiciones de símbolos y relocalizaciones que marcan direcciones que necesitan ser corregidas.
Pero tu programa no es solo un paquete. Incluso un simple “hello world” importa fmt, que a su vez importa io, os, reflect y docenas de otros paquetes. Cada paquete se compila por separado en su propio archivo objeto. Ninguno de estos archivos puede ejecutarse por sí solo.
Aquí es donde entra el linker. El trabajo del linker es tomar todos estos archivos objeto separados y combinarlos en un único ejecutable que tu sistema operativo pueda ejecutar.
Déjame mostrarte qué hace el linker y cómo lo hace.
Qué Hace el Linker
A alto nivel, el linker realiza cuatro tareas principales:
1. Resolución de Símbolos: Tu código llama a fmt.Println, pero esa función está definida en un archivo objeto diferente. El linker encuentra todas estas referencias entre archivos y las conecta.
2. Relocalización: ¿Recuerdas esas placeholders en el código máquina? El linker las parchea con direcciones reales ahora que sabe dónde vivirá todo en memoria.
3. Eliminación de Código Muerto: Si importas un paquete pero solo usas una función, el linker elimina todas las funciones no utilizadas. Esto mantiene tu binario pequeño.
4. Layout y Generación del Ejecutable: El linker decide dónde en memoria vivirá cada pieza de código y datos, luego escribe un ejecutable en el formato que tu SO espera (ELF en Linux, Mach-O en macOS, PE en Windows).
Veamos cada uno de estos pasos, empezando por cómo el linker descubre qué símbolos existen y dónde viven.
Resolución de Símbolos
Cada archivo objeto contiene símbolos—nombres que identifican funciones, variables globales y otros elementos del programa. Algunos símbolos están definidos en un archivo (el código o datos reales viven ahí), mientras que otros solo están referenciados (el código los usa, pero viven en otro lugar).
Déjame mostrarte a qué me refiero:
// main.go
package main
import "fmt"
func main() {
fmt.Println("Hello")
}
Cuando se compila, tu main.o contiene main.main—esa es tu función, completa con código máquina. Pero también referencia fmt.Println, y ese código no está aquí. Es solo un nombre apuntando a otro lugar.
Nota: En la práctica, el compilador hace inlining de
fmt.Println, así que no hay una referencia real entre paquetes en este caso. Pero el concepto aplica para funciones a las que no se les hace inlining.
En fmt.o, encontrarás la implementación real de fmt.Println. Pero ese archivo referencia io.Writer, os.Stdout y docenas más de símbolos de otros paquetes.
Cada paquete define algunos símbolos y referencia otros. El linker necesita emparejar todas estas referencias con sus definiciones. Para hacer eso, primero necesita construir una imagen completa de lo que existe.
El Loader: Construyendo un Índice Global de Símbolos
Antes de que el linker pueda hacer algo útil, necesita conocer cada símbolo en tu programa. Ese es el trabajo del Loader (src/cmd/link/internal/loader/
).
El Loader lee archivos objeto y construye un índice unificado de todos los símbolos. Empieza con tu paquete main, lee ese archivo objeto y descubre sus imports. Tu código usa fmt, así que ahora fmt necesita ser cargado. Y fmt importa io, os, reflect y otros. El Loader sigue siguiendo imports hasta que ha encontrado cada paquete del que depende tu programa. El paquete runtime siempre se carga también, ya que todo programa Go lo necesita.
Mientras lee cada archivo, el Loader registra cada símbolo y conecta referencias con definiciones. Cuando tu código llama a una función de otro paquete, el archivo objeto solo dice “necesito este símbolo”. El Loader lo busca y registra a dónde apunta. La mayoría de los símbolos se identifican por nombre, pero algunos—como los literales de string—son content-addressable, identificados por un hash de su contenido. Si dos paquetes usan "Hello", producen el mismo hash y comparten una única copia en el binario final.
El índice en sí es sencillo. Cada símbolo obtiene un ID entero único. El Loader mantiene unas pocas estructuras de datos clave: un mapeo del ID de símbolo a su ubicación (qué archivo objeto, qué índice local dentro de ese archivo), tablas de búsqueda para ir de un nombre como fmt.Println a su ID, y espacio para atributos como “¿es alcanzable este símbolo?” que se rellenan después. Los bytes reales de código y datos permanecen en los archivos objeto—el Loader solo registra dónde encontrarlos.
Al final, el Loader tiene una imagen completa: cada símbolo indexado, cada referencia resuelta. Puedes encontrar la lógica de carga en src/cmd/link/internal/loader/loader.go
.
Pero tener todo indexado no significa que necesitemos todo. Es hora de eliminar lo que sobra.
Eliminación de Código Muerto
El Loader indexó cada símbolo de cada paquete, pero probablemente no usas todos. Si importas fmt solo para llamar a Println, no necesitas las docenas de otras funciones en ese paquete.
El linker resuelve esto con dead code elimination. Empezando desde main.main, traza cada llamada a función y cada acceso a variable global, estableciendo ese atributo “¿es alcanzable este símbolo?” que mencionamos antes. Cuando termina, todo lo que no esté marcado se descarta. Si importaste un paquete con cincuenta funciones pero solo llamaste a una, las otras cuarenta y nueve desaparecen.
Por esto los binarios de Go se mantienen razonablemente pequeños a pesar del static linking. Puedes encontrar esta lógica en src/cmd/link/internal/ld/deadcode.go
.
Con los símbolos resueltos y el código muerto eliminado, el linker sabe exactamente qué necesita ir en el binario final. Pero hay un problema: el código máquina todavía tiene placeholders para símbolos que viven en otros paquetes.
Relocalización
Cuando el compilador generó código máquina para un paquete, conocía los símbolos dentro de ese paquete pero no los símbolos definidos en otro lugar. Cada llamada a una función en otro paquete, cada referencia a una variable de un módulo importado—esos son solo placeholders diciendo “rellena esto después”. El trabajo del linker ahora es averiguar dónde van realmente todos estos símbolos entre paquetes, y luego parchear esos placeholders con direcciones reales.
Esto crea una situación del huevo y la gallina: no puedes rellenar las direcciones hasta que sepas dónde está todo, pero necesitas colocar todo el código y datos primero para saber dónde está todo. El linker resuelve esto en dos pasadas: primero asigna direcciones a todo, luego vuelve y parchea el código.
Asignación de Direcciones
El linker organiza la memoria en secciones basándose en qué contiene cada símbolo y cómo se usará:
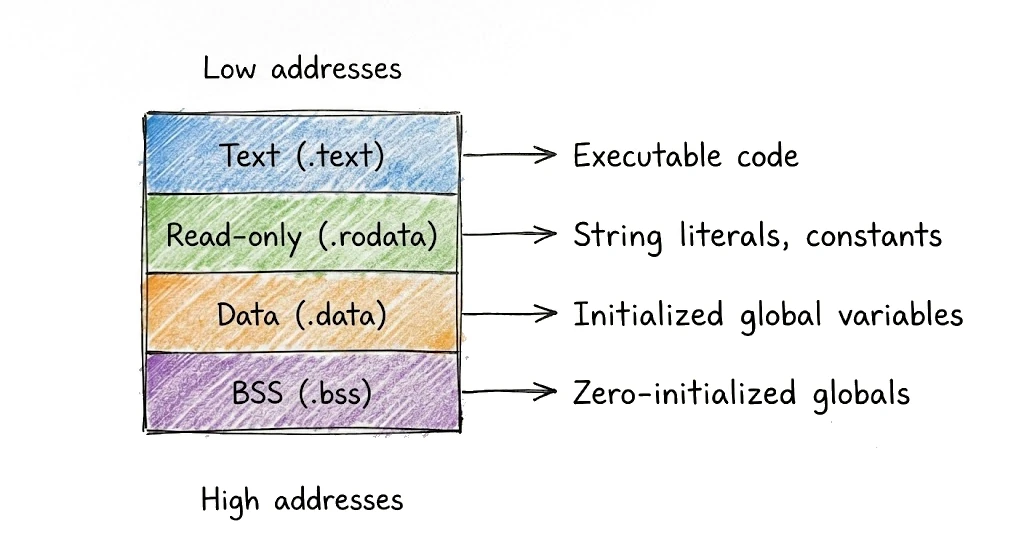
El linker procesa símbolos uno por uno, colocando cada uno en la siguiente dirección disponible en su sección. Las funciones se alinean a límites apropiados (típicamente 16 o 32 bytes dependiendo de la arquitectura) para eficiencia de caché. Los datos de solo lectura se agrupan para que puedan protegerse contra modificación. La sección .bss es especial—no ocupa espacio en el archivo ya que todo ahí son solo ceros, pero el SO asigna la memoria cuando el programa carga. Al final de esta pasada, cada símbolo tiene una dirección concreta.
Ahora que todo tiene una dirección, es hora de arreglar todos esos placeholders.
Parcheando Relocalizaciones
Cada placeholder tiene un registro de relocalización asociado que dice qué dirección de símbolo pertenece ahí. El linker recorre cada relocalización, busca la dirección del objetivo y la parchea. Para llamadas a funciones, la CPU espera un offset relativo (“salta 500 bytes hacia adelante”), así que el linker calcula la distancia entre el sitio de llamada y el objetivo. Para referencias a variables globales, escribe la dirección absoluta directamente. Cuando esta pasada termina, el código máquina está completo—cada placeholder reemplazado con una dirección real.
El linker ahora tiene código máquina completamente enlazado. Todo lo que queda es empaquetarlo en un archivo que el sistema operativo pueda ejecutar.
Generando el Ejecutable
Finalmente, el linker organiza todo en secciones, las agrupa en segmentos y escribe el archivo ejecutable. Veamos cómo funciona esta organización.
Secciones
El linker agrupa símbolos en secciones basándose en qué son y cómo se usarán:
.textcontiene código ejecutable—tus funciones, marcadas read-execute.rodatacontiene datos de solo lectura—literales de string, constantes, descriptores de tipo.datacontiene variables globales inicializadas—read-write.bsscontiene globales inicializadas a cero—read-write, pero no ocupa espacio en el archivo.noptrdatay.noptrbsscontienen datos que el garbage collector puede ignorar (sin punteros)
Go también genera secciones especiales para metadatos del runtime. La sección .gopclntab contiene la tabla PC-line—el mapeo de valores del contador de programa a archivo fuente y números de línea que hace que los stack traces funcionen y habilita reflection.
Pero las secciones son la organización interna del linker. El sistema operativo piensa en términos de segmentos.
Segmentos
Las secciones se agrupan en segmentos para la carga. Mientras las secciones son la vista del linker de los datos, los segmentos son la vista del loader del SO. Al SO no le importan las secciones individuales; mapea segmentos enteros en memoria con los permisos correctos.
Un ejecutable típico de Go tiene un segmento de texto (código + datos de solo lectura, mapeado read-execute) y un segmento de datos (datos escribibles + BSS, mapeado read-write). En algunas plataformas también hay un segmento separado de datos de solo lectura entre ellos para .rodata.
El layout de segmentos importa para la seguridad. Los sistemas modernos usan W^X (write xor execute)—la memoria puede ser escribible o ejecutable, pero no ambas. Al separar código y datos en diferentes segmentos con diferentes permisos, el linker habilita esta protección.
Con los segmentos definidos, el linker escribe todo a disco en un formato que el SO entiende.
Formato de Archivo y Carga
Diferentes sistemas operativos usan diferentes formatos de ejecutable—Linux usa ELF, macOS usa Mach-O, Windows usa PE. A pesar de las diferencias, todos contienen:
- Una cabecera identificando el formato de archivo y arquitectura
- Cabeceras de programa (o equivalente) describiendo segmentos a cargar
- Cabeceras de sección describiendo el contenido para debuggers y herramientas
- Los bytes reales de código y datos
- Opcionalmente, información de debug (formato DWARF)
Un detalle interesante: la cabecera especifica un entry point—donde el SO empieza a ejecutar—y no es tu función main. Es código de arranque del runtime de Go como _rt0_amd64_linux, que configura el stack, inicializa el allocator de memoria, arranca el garbage collector y lanza el scheduler antes de finalmente llamar a tu main.main.
Puedes encontrar el código de salida en src/cmd/link/internal/ld/elf.go
y archivos similares para otros formatos. Si quieres explorar la estructura final de un binario de Go en más detalle, echa un vistazo a mi charla Deep dive into a Go binary
de GopherCon UK.
Todo lo que hemos discutido hasta ahora asume el caso por defecto: un ejecutable independiente con todo incluido. Pero el linker puede producir otros tipos de salida también.
Static Linking, Dynamic Linking y Build Modes
Go prefiere static linking—empaquetar todo en un único binario autocontenido. El runtime de Go, la biblioteca estándar, todas tus dependencias: todo está compilado dentro. Sin dependencias externas significa que puedes copiar el binario a otra máquina y simplemente funciona.
Cuando usas cgo, Go tiene que enlazar dinámicamente contra bibliotecas del sistema como libc. El linker añade una sección .dynamic con tablas de símbolos, nombres de bibliotecas y entradas de relocalización. También especifica un interpreter—la ruta al dynamic linker (/lib64/ld-linux-x86-64.so.2 en Linux). Cuando ejecutas el programa, el kernel carga el dynamic linker primero, que resuelve símbolos externos y carga bibliotecas compartidas antes de saltar a tu código.
Con flags -buildmode, el linker puede producir otros tipos de salida: bibliotecas estáticas compatibles con C (c-archive), bibliotecas compartidas (c-shared), o plugins de Go (plugin). Cada modo cambia qué se exporta, cómo se inicializa el runtime y qué formato de archivo se escribe.
Ahora que hemos visto todas las piezas, veámoslas trabajar juntas en un ejemplo concreto.
Recorriendo un Ejemplo Completo
Tracemos un programa simple con dos paquetes a través de todo el proceso de linking.
main.go:
package main
import "example/greeter"
func main() {
greeter.Hello()
}
greeter/greeter.go:
package greeter
import "fmt"
//go:noinline
func Hello() {
fmt.Println("Hello")
}
Nota: La directiva
//go:noinlineevita que el compilador haga inlining deHelloenmain.main. Sin ella, el compilador haría inlining de la función y no habría llamada entre paquetes para que el linker resuelva.
Sigamos este programa a través de cada fase del linking.
Después de la Compilación
El compilador produce archivos objeto separados. main.o contiene main.main y tiene una referencia a example/greeter.Hello—llama a esa función pero no tiene el código. Hay una relocalización marcando dónde necesita rellenarse la dirección de la llamada.
greeter.o contiene example/greeter.Hello, que a su vez referencia fmt.Fprintln (eso es lo que fmt.Println llama internamente). Y fmt.a (el archivo para el paquete fmt) tiene la implementación real, junto con referencias a io.Writer, os.Stdout y más.
El linker empieza cargando todas estas piezas y averiguando qué es qué.
Cargando y Resolviendo
El linker carga todos estos archivos y construye una tabla de símbolos. Nota que los nombres de símbolos incluyen la ruta completa del módulo:
Symbol Table:
main.main → defined in main.o
example/greeter.Hello → defined in greeter.o
fmt.Fprintln → defined in fmt.a
(más cientos del runtime y biblioteca estándar)
Cada referencia puede emparejarse con una definición. Si faltara algo, el linker se detendría aquí con un error de símbolo indefinido.
A continuación, el linker averigua qué se usa realmente.
Eliminación de Código Muerto
Empezando desde main.main, el linker traza todas las llamadas:
main.main → llama a example/greeter.Hello
example/greeter.Hello → llama a fmt.Fprintln
fmt.Fprintln → llama a métodos de io.Writer, usa os.Stdout
...
Todo en esta cadena se marca como alcanzable. Cualquier cosa fuera de la cadena—funciones de paquetes que importaste pero nunca usaste realmente—se descarta.
Con el conjunto de símbolos alcanzables determinado, el linker asigna a cada uno una dirección.
Asignando Direcciones
Ahora el linker coloca todos los símbolos alcanzables en memoria. Así es como se ve para nuestro ejemplo (direcciones de una compilación real):
Text section (starting at 0x401000):
0x46f1e0: _rt0_amd64_linux (entry point)
0x439040: runtime.main
0x491b20: main.main
0x491ac0: example/greeter.Hello
0x48cac0: fmt.Fprintln
...
Data section (starting at 0x554000):
0x55e148: os.Stdout
...
Ahora el linker puede parchear todas las placeholders en el código máquina.
Parcheando Relocalizaciones
Con las direcciones asignadas, el linker vuelve y rellena todos los placeholders.
En main.main, hay una llamada a example/greeter.Hello. Podemos verlo en el desensamblado:
TEXT main.main(SB)
0x491b20 CMPQ SP, 0x10(R14)
0x491b24 JBE 0x491b31
0x491b26 PUSHQ BP
0x491b27 MOVQ SP, BP
0x491b2a CALL example/greeter.Hello(SB) ← parcheado con offset a 0x491ac0
0x491b2f POPQ BP
0x491b30 RET
La instrucción CALL en 0x491b2a contiene un offset relativo que salta a example/greeter.Hello en 0x491ac0. Lo mismo para la llamada de greeter.Hello a fmt.Fprintln—el linker calcula el offset y lo parchea.
Ahora todos los saltos y llamadas apuntan a los lugares correctos.
Todo lo que queda es escribir el archivo final.
Escribiendo el Ejecutable
Finalmente, el linker escribe todo. En Linux, podemos inspeccionar el resultado con readelf (en macOS, usa otool -h):
$ readelf -h ./example
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Type: EXEC (Executable file)
Machine: Advanced Micro Devices X86-64
Entry point address: 0x46f1e0
Number of program headers: 6
Number of section headers: 25
...
Ahí está—un ejecutable completo e independiente. El entry point 0x46f1e0 es _rt0_amd64_linux, el código de arranque del runtime que eventualmente llamará a nuestro main.main.
Si quieres ver esto sucediendo en tu propio código, hay algunos comandos útiles para explorar.
Pruébalo Tú Mismo
Si quieres mirar detrás del telón, hay algunos comandos que te permiten ver qué está haciendo el linker.
Para observar el linker trabajar, pasa -v a través de ldflags:
$ go build -ldflags="-v" .
# example
build mode: exe, symbol table: on, DWARF: on
HEADER = -H5 -T0x401000 -R0x1000
107437 symbols, 20441 reachable
48122 package symbols, 39987 hashed symbols, 14790 non-package symbols, 4538 external symbols
112153 liveness data
Verás cuántos símbolos se cargaron, cuántos son alcanzables después de la eliminación de código muerto y otra información de compilación.
Una vez que tienes un binario, puedes inspeccionar su tabla de símbolos con nm:
go tool nm ./example | less
Esto vuelca cada símbolo en el ejecutable junto con su dirección. Es mucha salida—incluso nuestro programa simple tiene más de 2000 símbolos del runtime.
Para ver cómo las secciones están dispuestas en memoria, usa la herramienta de inspección de binarios de tu plataforma:
readelf -S ./example # Linux
otool -l ./example # macOS
Y si quieres ver todo el proceso de compilación, incluyendo el comando exacto de link:
go clean && go build -x .
El go clean asegura que obtengas la salida completa—sin él, compilaciones cacheadas podrían saltarse pasos.
Esto imprime cada comando que ejecuta la herramienta go. Verás las invocaciones del compilador, luego la invocación del linker con todos sus flags. Es una buena manera de entender qué está pasando bajo go build.
Resumamos lo que hemos aprendido.
Resumen
El linker es el paso final en el proceso de compilación. Toma archivos objeto separados y los combina en un único ejecutable:
Resolución de Símbolos: El Loader construye un índice global de cada símbolo en tu programa, siguiendo imports recursivamente y conectando referencias con definiciones. Los símbolos content-addressable permiten que datos idénticos (como literales de string) se compartan entre paquetes.
Eliminación de Código Muerto: Empezando desde
main.main, el linker traza alcanzabilidad y descarta todo lo que no se usa. Por esto los binarios de Go se mantienen razonablemente pequeños a pesar del static linking.Relocalización: El linker asigna a cada símbolo una dirección concreta, organizándolos en secciones (
.text,.rodata,.data,.bss), luego parchea todas las placeholders en el código máquina.Generación del Ejecutable: Las secciones se agrupan en segmentos con permisos apropiados (W^X), y el linker escribe todo en el formato específico del SO (ELF, Mach-O, PE). El entry point no es tu
main—es código de arranque del runtime que inicializa el runtime de Go antes de llamar a tu código.
El linker de Go también maneja diferentes modos de compilación—desde el ejecutable con static linking por defecto hasta archivos C, bibliotecas compartidas y plugins.
Si quieres profundizar más en el linker, explora src/cmd/link/internal/ld/
. El código está bien documentado, y ver cómo funciona un linker de producción real es fascinante.
¡Y con esto, hemos completado nuestro viaje a través del compilador de Go! Desde el código fuente pasando por scanning, parsing, type checking, optimización de IR, transformación SSA, generación de código y finalmente linking—tu programa Go es ahora un ejecutable independiente listo para ejecutar.
Pero la historia no termina aquí. Ese ejecutable contiene el runtime de Go: el scheduler que gestiona goroutines, el garbage collector que reclama memoria, el allocator de memoria, y toda la maquinaria que hace funcionar el modelo de concurrencia de Go. En la próxima serie, exploraremos cómo el runtime da vida a tu programa. ¡Estad atentos!