
Cada vez que guardas un documento, descargas una foto o instalas una aplicación, estás confiando en un filesystem para mantener tus datos a salvo. Piénsalo: los filesystems son esa capa invisible entre tus aplicaciones y el hardware de almacenamiento. Convierten un mar de bloques numerados en el familiar mundo de archivos y carpetas que todos damos por sentado.
Pero, ¿qué hace exactamente un filesystem? ¿Y qué lo hace tan difícil de implementar correctamente? En esta serie, vamos a explorar filesystems como FAT32, ext4, Btrfs y otros. Pero antes de llegar ahí, quiero construir una base sólida contigo. Empezaremos desde lo más bajo —cómo funciona realmente el hardware de almacenamiento— y subiremos hasta las abstracciones que proporcionan los filesystems.
Al final de este artículo, tendrás una buena comprensión de los conceptos fundamentales con los que todo filesystem tiene que lidiar. Créeme, esto hará que el resto de la serie sea mucho más fácil de seguir.
Así que empecemos donde todo empieza: con el hardware de almacenamiento en bruto.
La Materia Prima: Hardware de Almacenamiento
¿Con qué tiene que trabajar realmente un filesystem?
Sectores: La Unidad Más Pequeña
Ya sea que estés tratando con un disco duro tradicional (HDD) o una unidad de estado sólido (SSD), todos se presentan al sistema operativo de la misma manera: como un array lineal de sectores. Un sector es simplemente la unidad más pequeña que el hardware puede leer o escribir.
Los sectores típicamente son de 512 bytes o 4096 bytes. El tamaño más grande tiende a ser más eficiente para unidades de alta capacidad —hay menos overhead para corrección de errores y direccionamiento.
Ahora viene la clave, y es importante: el disco no sabe qué hay en estos sectores. Para el hardware, el sector 0 y el sector 1.000.000 se ven exactamente igual —son simplemente ranuras numeradas que contienen bytes. El disco no tiene absolutamente ningún concepto de “archivos” o “directorios”. Eso es enteramente trabajo del filesystem.
Pero antes de que el filesystem entre en juego, el sistema operativo necesita una forma de comunicarse con estos discos.
Cómo lo Ve el Sistema Operativo
Cuando conectas un disco, el sistema operativo lo ve como un block device —básicamente un dispositivo que lee y escribe bloques de tamaño fijo. El SO puede pedirle al disco que lea un sector específico, escriba datos en un rango de sectores, o que le diga cuántos sectores tiene. ¡Y eso es prácticamente todo! La interfaz de block device es maravillosamente simple:
// Conceptualmente, un block device proporciona:
size_t read_sectors(uint64_t start_sector, size_t count, void *buffer);
size_t write_sectors(uint64_t start_sector, size_t count, void *buffer);
uint64_t get_sector_count(void);
size_t get_sector_size(void); // Normalmente 512 o 4096
Un disco de 1TB con sectores de 512 bytes tiene aproximadamente 2 mil millones de sectores. Un disco de 1TB con sectores de 4KB tiene aproximadamente 250 millones de sectores. De cualquier manera, estás viendo un array gigante de ranuras numeradas.
Ahora, esta interfaz simple oculta cierta complejidad interesante que ocurre dentro del propio disco.
HDDs vs SSDs: Misma Interfaz, Diferentes Internos
Los discos duros (HDDs) almacenan datos magnéticamente en platos giratorios. Un cabezal de lectura/escritura se mueve físicamente por la superficie para acceder a diferentes sectores. Debido a este movimiento mecánico, el acceso secuencial es rápido —leer los sectores 1000-2000 en orden no es problema ya que el cabezal apenas se mueve. Pero el acceso aleatorio es lento. Saltar del sector 1000 al sector 500.000 significa mover físicamente el cabezal a través del plato, y eso lleva tiempo.
Las unidades de estado sólido (SSDs) usan memoria flash sin partes móviles. Pueden acceder a cualquier sector igual de rápido (bueno, más o menos). Pero los SSDs tienen sus propias peculiaridades. No pueden simplemente sobrescribir datos directamente —tienen que borrar primero, luego escribir. Y el borrado ocurre en unidades grandes llamadas “erase blocks”, típicamente de 128KB a 512KB. El controlador del SSD maneja toda esta complejidad internamente mediante wear leveling y garbage collection, así que tú no tienes que pensar en ello.
Aquí está la parte interesante: a pesar de estas enormes diferencias bajo el capó, ambos tipos de discos presentan exactamente la misma interfaz de block device al sistema operativo. El filesystem no necesita saber si está hablando con un disco giratorio o memoria flash —simplemente lee y escribe sectores.
Pero antes de poder poner un filesystem en este mar de sectores, normalmente necesitamos dividirlo en piezas manejables.
Dividiendo el Disco: Particiones
Una partición es simplemente un rango contiguo de sectores que decides tratar como una unidad independiente.
¿Por qué querrías particionar un disco? Bueno, quizás quieres ejecutar tanto Windows como Linux en el mismo disco físico —Windows usando NTFS en una partición, Linux usando ext4 en otra. O quizás simplemente quieres mantener tu sistema operativo separado de tus datos, para que si necesitas reinstalar el SO, tus archivos permanezcan a salvo. Las particiones también proporcionan aislamiento: si una partición se corrompe, las otras permanecen intactas. Y a veces simplemente necesitas diferentes particiones para diferentes propósitos —una partición de swap aquí, una partición de arranque allá, una gran partición de datos para todo lo demás.
Por supuesto, esto plantea una pregunta: ¿cómo sabe el sistema dónde empieza y termina cada partición?
La Tabla de Particiones
Ahí es donde entra la tabla de particiones. Es una pequeña estructura de datos, normalmente justo al principio del disco, que describe cómo está dividido el disco. Hay dos formatos comunes que encontrarás:
MBR (Master Boot Record) es el formato heredado de 1983:
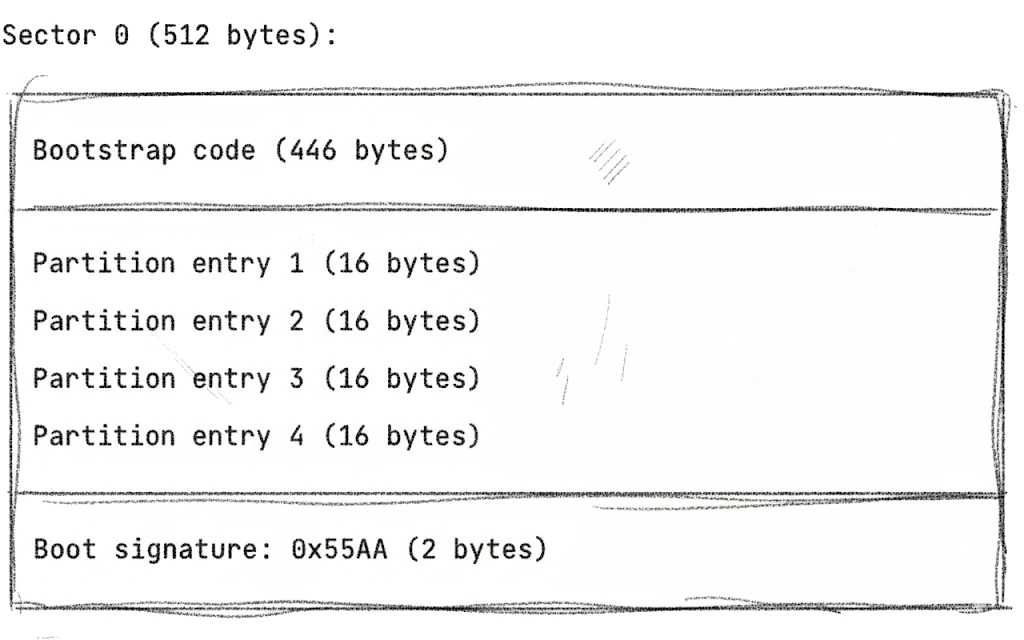
Vamos a desglosarlo. El código de arranque ocupa la mayor parte del espacio —446 bytes donde instalas tu boot loader (GRUB, LILO o similar) para iniciar tu sistema operativo.
Las cuatro entradas de partición vienen después, 16 bytes cada una. Cada entrada te dice dónde empieza la partición, qué tamaño tiene en sectores, qué tipo es (0x07 para NTFS, 0x83 para Linux, etc.), y si es arrancable.
Finalmente, está la firma de arranque —los bytes mágicos 0x55AA que marcan esto como un MBR válido.
MBR funciona, pero tiene algunas limitaciones frustrantes. Solo puedes tener 4 particiones primarias (o 3 primarias más 1 extendida con particiones lógicas dentro —se complica). El tamaño máximo de disco es 2TB debido a las direcciones de sector de 32 bits, lo cual es un problema real con los discos modernos. Y no hay redundancia —si el sector 0 se corrompe, pierdes toda la tabla de particiones.
GPT (GUID Partition Table) es el formato moderno que soluciona estos problemas:
Sector 0: MBR Protector (para compatibilidad hacia atrás)
Sector 1: Cabecera GPT
Sectores 2-33: Entradas de partición (128 entradas × 128 bytes cada una)
...
Sectores N-33 a N-2: Copia de seguridad de entradas de partición
Sector N-1: Copia de seguridad de cabecera GPT
El MBR Protector en el sector 0 hace que el disco parezca tener una partición que abarca todo el disco, para que las herramientas antiguas que solo entienden MBR no sobrescriban accidentalmente tus datos GPT. La Cabecera GPT contiene el identificador único del disco, la ubicación de las entradas de partición, y checksums para verificación de integridad.
GPT te da hasta 128 particiones por defecto —muchas más de las que probablemente necesitarás jamás. Soporta discos mayores de 2TB gracias a direcciones de 64 bits. Cada partición obtiene un GUID único, lo que hace la identificación mucho más fiable. Y aquí está la parte realmente buena: GPT almacena una copia de seguridad de la tabla de particiones al final del disco, más checksums CRC32 para detectar corrupción. Mucho más robusto que MBR.
Cuando creas una partición, básicamente estás diciendo: “Los sectores 2048 a 500.000.000 pertenecen a la partición 1”. El filesystem entonces puede usar esos sectores como quiera.
Así que ahora tenemos una partición —un trozo dedicado de sectores. ¿Qué pasa después?
Dentro de una Partición
Una vez que tienes una partición, la formateas con un filesystem. El filesystem toma posesión de esos sectores y los organiza según sus propias reglas.
Aquí hay algo interesante: desde la perspectiva del filesystem, no le importa que esté en una partición —simplemente ve un block device con un cierto número de sectores. El filesystem escribe sus estructuras empezando en el sector 0 de la partición (que en realidad podría ser el sector 2048 del disco físico, pero el filesystem no necesita saber eso).
Ya tenemos nuestra materia prima organizada —sectores organizados en particiones. Es hora de ver qué hace realmente un filesystem con todo esto.
Qué Hacen Realmente los Filesystems
Vale, ahora entendemos con qué tiene que trabajar un filesystem: un array lineal de sectores numerados. Pero tú y yo no queremos pensar en sectores —¡queremos archivos y directorios! El filesystem cierra esta brecha proporcionando varios servicios esenciales.
1. Nombrado: De Números a Nombres
El trabajo más fundamental de un filesystem es mapear nombres a datos. En lugar de decir “lee los sectores 50.000-50.007”, puedes decir “lee /home/alice/photo.jpg”. Mucho mejor, ¿verdad?
Para que esto funcione, el filesystem necesita un namespace (la estructura jerárquica de directorios y archivos), entradas de directorio (estructuras de datos que mapean nombres a metadatos de archivos), y resolución de rutas (la capacidad de recorrer el árbol de directorios para encontrar un archivo).
Déjame explicarte qué pasa realmente cuando abres /home/alice/photo.jpg. El filesystem empieza encontrando el directorio raíz. Luego busca “home” en el directorio raíz para obtener su ubicación. Lee el directorio “home” y busca “alice” para obtener esa ubicación. Lee el directorio “alice”, busca “photo.jpg”, obtiene los metadatos del archivo, y finalmente devuelve la ubicación de los datos del archivo al llamador.
¡Son muchos pasos! Cada filesystem implementa esta danza de forma diferente, pero todos resuelven el mismo problema fundamental: convertir rutas legibles por humanos en direcciones de sector.
Pero el nombrado es solo el principio. El filesystem también necesita averiguar dónde poner realmente todos estos datos.
2. Asignación de Espacio: ¿Quién Obtiene Qué?
Cuando creas un nuevo archivo o añades a uno existente, el filesystem necesita encontrar espacio libre rápidamente.
Esto suena bastante simple, pero piensa en los desafíos por un momento. Un disco de 1TB tiene millones de unidades de asignación —¿cómo buscas a través de todo eso eficientemente? Los archivos crecen y encogen todo el tiempo, creando fragmentación —¿cómo lidias con eso? Múltiples procesos podrían estar escribiendo simultáneamente —¿cómo evitas conflictos?
Diferentes filesystems abordan esto de diferentes maneras. Algunos usan bitmaps, donde cada bit representa un bloque (0 significa libre, 1 significa usado). Es simple y elegante, pero puede ser lento de escanear. Otros usan listas de bloques libres —una lista enlazada de bloques libres. Rápido para asignar, pero la fragmentación se convierte en un verdadero dolor de cabeza. Filesystems más sofisticados usan B-trees o estructuras similares para búsqueda rápida. Son más complejos de implementar, pero escalan mucho mejor. Y luego está el enfoque FAT —una tabla donde cada entrada apunta al siguiente bloque en una cadena. Veremos mucho más de ese más adelante en esta serie.
Así que podemos nombrar archivos y asignarles espacio. Pero hay más en un archivo que solo su contenido.
3. Metadatos: Más Que Solo Contenido
¿Cuántos bytes tiene este archivo? ¿Cuándo fue creado, modificado o accedido por última vez? ¿Quién puede leerlo, escribirlo o ejecutarlo? ¿A qué usuario pertenece? ¿Es un archivo regular, un directorio, un symlink, o algo completamente diferente?
El filesystem tiene que almacenar todos estos metadatos en algún lugar y mantenerlos sincronizados con el contenido real del archivo. ¡Eso es más complicado de lo que parece! Los filesystems tipo Unix usan inodes (nodos índice) para esto. Los filesystems FAT almacenan metadatos en entradas de directorio, aunque con información bastante limitada. NTFS usa registros de Master File Table. Cada enfoque tiene sus propios compromisos, que exploraremos en detalle cuando lleguemos a esos filesystems específicos.
Todo esto —nombrado, asignación, metadatos— funciona genial cuando todo va bien. Pero, ¿qué pasa cuando las cosas van mal?
4. Recuperación de Fallos: Cuando las Cosas Van Mal
Aquí hay un pensamiento aterrador: ¿qué pasa si falla la corriente mientras estás en medio de escribir un archivo? El filesystem podría quedar en un estado inconsistente —algunos bloques escritos, otros no, metadatos completamente desincronizados con los datos reales.
Los filesystems usan varias estrategias para manejar este escenario de pesadilla:
Journaling: Antes de hacer cualquier cambio, escribe un log de lo que pretendes hacer. Si ocurre un fallo, puedes reproducir el journal para restaurar la consistencia. Esto es lo que hacen ext4, NTFS y XFS, y funciona realmente bien.
Copy-on-write (CoW): Nunca modifiques datos en su lugar —siempre escribe en nuevas ubicaciones. La versión antigua y consistente permanece perfectamente válida hasta que la nueva esté completa. Así es como funcionan Btrfs y ZFS, y es bastante ingenioso.
fsck (filesystem check): Escanea todo el filesystem buscando inconsistencias e intenta arreglarlas. Es dolorosamente lento y era el método principal de recuperación antes de que llegara el journaling. Hoy en día es principalmente un respaldo.
Sin alguna forma de recuperación de fallos, un solo corte de luz podría corromper todo tu filesystem. Por eso los filesystems modernos invierten tanto en esta área.
Ahora que sabemos qué necesitan lograr los filesystems, veamos los bloques de construcción reales que usan para hacer el trabajo.
Conceptos Comunes Entre Filesystems
Los detalles varían de un filesystem a otro, pero los conceptos subyacentes son notablemente similares.
El Superblock / Boot Sector
Todo filesystem necesita un punto de partida —alguna ubicación fija donde el SO pueda encontrar información básica sobre el filesystem. Esto típicamente se llama superblock (esa es la terminología Unix) o boot sector (terminología DOS/Windows).
¿Qué hay en esta estructura? Primero, normalmente hay un magic number —un valor especial que identifica el tipo de filesystem. Así es como el SO sabe si está viendo ext4 o NTFS o algo completamente diferente. Luego está la información de geometría: el tamaño de bloque, número total de bloques, cuántos están libres. El superblock también te dice dónde encontrar el directorio raíz, qué características opcionales están habilitadas, e incluye identificadores únicos como UUIDs o etiquetas de volumen.
// Conceptualmente, todo filesystem tiene algo como esto:
struct superblock {
uint32_t magic; // Identificador de filesystem
uint32_t block_size; // Bytes por bloque
uint64_t total_blocks; // Total de bloques en el filesystem
uint64_t free_blocks; // Bloques disponibles
uint64_t root_location; // Dónde vive el directorio raíz
// ... más campos
};
Como esta estructura es tan crítica, los filesystems a menudo almacenan múltiples copias en diferentes ubicaciones del disco. Si una copia se corrompe, puedes recuperar desde una copia de seguridad. Inteligente, ¿verdad?
El superblock nos dice lo básico, pero hay otro concepto fundamental que necesitamos entender: cómo los filesystems realmente dividen el espacio del disco.
Bloques: La Unidad de Asignación
Mientras el hardware trabaja en sectores (512 o 4096 bytes), los filesystems típicamente trabajan en bloques más grandes (también llamados clusters en terminología FAT). Comúnmente verás bloques de 1KB en algunos filesystems más pequeños, bloques de 4KB en la mayoría de sistemas modernos (coincide bien con el tamaño de página x86 y el tamaño de sector moderno), y ocasionalmente bloques de 8KB a 64KB para archivos grandes o cargas de trabajo especializadas.
¿Por qué no usar sectores directamente? Bueno, piensa en un archivo de 1GB. Con bloques de 4KB, necesitas 262.144 entradas de asignación para rastrearlo. Con sectores de 512 bytes, necesitarías 2.097.152 entradas —¡eso es mucha más contabilidad! Los bloques más grandes también se alinean bien con páginas de memoria, erase blocks de SSD, y sectores de disco modernos. Y las potencias de dos hacen los cálculos de direcciones rápidos.
¿El compromiso? Los bloques más grandes desperdician espacio para archivos pequeños. Un archivo de 100 bytes en un bloque de 4KB desperdicia 3.996 bytes. Ay. Algunos filesystems como ext4 intentan mitigar esto con técnicas como datos inline o tail packing, pero siempre es un acto de equilibrio.
Hemos hablado de bloques para almacenar contenido de archivos, pero ¿qué pasa con todos esos metadatos que mencionamos antes? Eso también necesita vivir en algún lugar.
Estructuras de Metadatos de Archivos
Todo filesystem necesita almacenar metadatos sobre cada archivo en algún lugar. Hay dos enfoques principales que verás.
Los filesystems tipo Unix (ext4, XFS, Btrfs) usan inodes, o nodos índice. Un inode contiene todos los metadatos sobre un archivo excepto el nombre del archivo —el tipo de archivo y permisos, el propietario y grupo, el tamaño, timestamps, y punteros a los bloques de datos reales.
// Estructura de inode simplificada
struct inode {
uint16_t mode; // Tipo + permisos
uint16_t uid; // Propietario
uint32_t size; // Tamaño del archivo
uint32_t atime; // Tiempo de acceso
uint32_t mtime; // Tiempo de modificación
uint32_t ctime; // Tiempo de cambio (metadatos)
uint32_t blocks[15]; // Punteros a bloques de datos
};
Espera, ¿dónde está el nombre del archivo? Se almacena por separado, en el directorio padre. Esto puede parecer raro al principio, pero permite algo genial: hard links. Múltiples entradas de directorio pueden apuntar al mismo inode, así que tienes un archivo con muchos nombres.
Los filesystems FAT toman un enfoque diferente: todos los metadatos viven directamente en la entrada de directorio junto con el nombre del archivo. Esto es más simple de entender, pero significa que no puedes tener hard links o permisos estilo Unix.
Hablando de entradas de directorio, veamos más de cerca cómo funcionan los propios directorios.
Directorios: La Estructura del Namespace
Aquí hay algo que podría sorprenderte: un directorio (o carpeta) es realmente solo un tipo especial de archivo. Contiene una lista de entradas que mapean nombres a archivos —cada entrada tiene un nombre de archivo y una referencia a los metadatos del archivo (como un número de inode o número de cluster).
Cómo se implementan los directorios varía bastante. FAT32 usa una simple lista lineal, que funciona bien pero se vuelve lenta con directorios grandes. Algunos filesystems usan tablas hash para búsquedas rápidas, como el htree de ext3. Otros usan B-trees, que permanecen ordenados y eficientes para todas las operaciones —eso es lo que hacen Btrfs y XFS.
El directorio raíz es especial —su ubicación tiene que ser conocida sin buscar nada más. Por eso el superblock siempre contiene un puntero a él.
Hay una pieza más de contabilidad crítica que todo filesystem necesita manejar: saber qué bloques están disponibles y cuáles ya están ocupados.
Seguimiento de Espacio Libre
Hay algunos enfoques comunes para resolver este problema.
El más simple es un bitmap —un array donde cada bit representa un bloque:
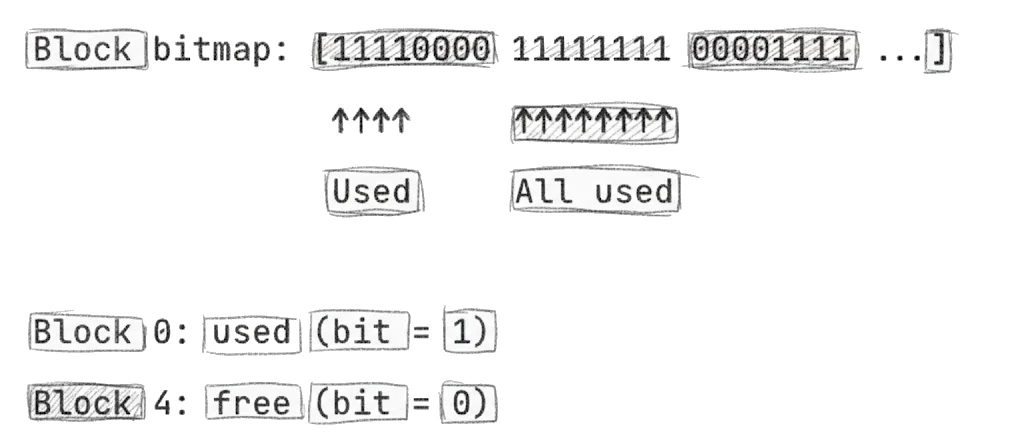
Los bitmaps son simples, compactos, y facilitan encontrar espacio libre contiguo. La desventaja es que tienes que escanear todo el bitmap para contar bloques libres.
Otro enfoque es una lista de bloques libres —una lista enlazada de bloques libres. La asignación es O(1) ya que simplemente tomas de la cabeza de la lista. Pero es difícil encontrar espacio contiguo, y la fragmentación se convierte en un problema real.
Filesystems más sofisticados usan un B-tree de extents libres —una estructura de árbol que rastrea rangos libres. Esto te da asignación rápida y facilita encontrar grandes regiones contiguas, pero es más complejo de implementar y hay overhead para mantener el árbol.
La mayoría de filesystems modernos realmente combinan estos enfoques —bitmaps para decisiones de asignación a pequeña escala, con estructuras adicionales como el buddy allocator de ext4 o los B-trees de espacio libre de XFS para eficiencia. Eliges la herramienta correcta para cada trabajo.
A estas alturas, podrías estar preguntándote: si todos los filesystems necesitan resolver los mismos problemas, ¿por qué hay tantos diferentes? La respuesta se reduce a compromisos.
Los Compromisos Fundamentales
Todo filesystem hace compromisos. No hay filesystem perfecto —solo diferentes optimizados para diferentes cosas. Entender estos compromisos te ayuda a apreciar por qué existen tantos filesystems diferentes.
Simplicidad vs Características
Considera FAT32. Es tremendamente simple —esencialmente solo una lista enlazada (la FAT) más entradas de directorio lineales. Es tan fácil de implementar que todos los dispositivos del planeta lo soportan. Pero renuncias a permisos, journaling, soporte de archivos grandes, y manejo eficiente de directorios grandes.
Btrfs es lo opuesto. Está lleno de características con copy-on-write, snapshots, RAID integrado, compresión y checksums. Pero es complejo, con múltiples B-trees y gestión de espacio sofisticada. Cuando ocurren bugs, son más difíciles de encontrar y arreglar.
Simplicidad versus características es solo un eje. Hay otra tensión que es posiblemente aún más importante.
Rendimiento vs Fiabilidad
Aquí es donde las cosas se ponen realmente interesantes. Delayed allocation —escribir a memoria primero, asignar bloques de disco después— mejora el rendimiento significativamente, pero arriesgas pérdida de datos si el sistema falla antes de que los datos lleguen al disco. Las escrituras síncronas garantizan durabilidad, tus datos están definitivamente a salvo, pero son dolorosamente lentas. El journaling añade algo de overhead pero permite recuperación rápida después de un fallo. Copy-on-write nunca pierde tus datos antiguos, lo cual es fantástico para fiabilidad, pero causa amplificación de escritura ya que siempre estás escribiendo en nuevas ubicaciones.
Cada filesystem elige un punto en estos espectros basándose en para qué está optimizando.
Y luego está la eterna lucha entre hacer las cosas de la manera nueva y asegurar que todo siga funcionando junto.
Compatibilidad vs Innovación
El límite de 4GB de FAT32 y la falta de permisos son frustrantes, pero su soporte universal es absolutamente inigualable —todos los dispositivos del planeta leen FAT32. Las características específicas de Linux de ext4 como extents, delayed allocation, y journaling son geniales cuando estás en Linux, pero completamente inútiles si necesitas leer el disco en Windows. exFAT intenta cerrar la brecha —soporta archivos más grandes que FAT32, es más simple que NTFS, y está licenciado para uso multiplataforma.
Estos compromisos son exactamente por qué tenemos tantos filesystems que explorar. Déjame darte un adelanto de hacia dónde vamos.
Lo Que Viene en Esta Serie
Ahora que entiendes los fundamentos, estamos listos para sumergirnos en filesystems específicos. En cada artículo, te mostraré exactamente cómo ese filesystem organiza los datos en el disco.
Empezaremos con FAT32, el estándar universal. Veremos cómo su hermosa simplicidad —solo una lista enlazada en disco— conquistó el mundo de los medios extraíbles. Luego veremos ext4, el caballo de batalla de Linux, explorando grupos de bloques, árboles de extents, y cómo equilibra compatibilidad con características modernas.
Examinaremos NTFS, el filesystem de Windows, viendo la Master File Table, directorios B-tree, y cómo todo (incluso los metadatos) se trata como un archivo. Exploraremos XFS, la opción de alto rendimiento, y veremos cómo los grupos de asignación y B-trees por todas partes permiten escalabilidad masiva.
Luego entraremos en los filesystems copy-on-write: Btrfs, el filesystem revolucionario donde nunca modificar datos en su lugar permite snapshots, checksums, y auto-reparación; y ZFS, la potencia empresarial con almacenamiento en pools, checksums jerárquicos, y una reputación como el filesystem más fiable que existe.
Finalmente, veremos APFS, el filesystem moderno de Apple, y veremos cómo está optimizado para almacenamiento flash, cifrado, y el ecosistema Apple.
Cada filesystem representa diferentes decisiones de diseño y compromisos. Al entender cómo funcionan internamente, estarás mucho mejor equipado para elegir el correcto para tus necesidades —y para solucionar problemas cuando inevitablemente las cosas vayan mal.
Pero antes de sumergirnos en todo eso, asegurémonos de que tenemos los fundamentos sólidos.
Resumen
Muy bien, recapitulemos lo que cubrimos antes de sumergirnos en filesystems específicos.
Empezamos desde abajo con el hardware de almacenamiento, que presenta una interfaz sorprendentemente simple: solo un array lineal de sectores numerados, típicamente de 512 o 4096 bytes cada uno. Al disco no le importa qué hay en esos sectores —eso es enteramente problema del filesystem.
Vimos las particiones, que dividen un disco físico en unidades lógicas, cada una formateada con su propio filesystem. La tabla de particiones (ya sea el formato heredado MBR o el formato moderno GPT) describe cómo está dividido el disco.
Luego exploramos qué hacen realmente los filesystems. Proporcionan cuatro servicios esenciales: nombrado (mapear rutas como /home/alice/photo.jpg a ubicaciones de datos reales), asignación (rastrear y asignar espacio libre), metadatos (almacenar atributos de archivo como tamaño, permisos y timestamps), y recuperación de fallos (mantener consistencia después de cortes de luz o fallos del sistema).
Finalmente, vimos las estructuras comunes que aparecen en casi todos los filesystems: el superblock o boot sector que sirve como punto de partida del filesystem, bloques o clusters como unidad de asignación, inodes o entradas de directorio para almacenar metadatos, directorios para mapear nombres a archivos, y varios enfoques para rastrear espacio libre.
Con esta base en su lugar, estás listo para ver cómo los filesystems reales ponen estos conceptos en práctica. Empecemos con el más simple y universal: FAT32.